ヒューマン・インタラクション
基盤技術コンソーシアム
コラムCOLUMN
増え続ける画像生成AI--2023年もテックシーンの話題に
ディープニューラルネットと自然言語モデルから誕生
海外動向
清水 計宏
2022年を賑わせた主なテクノロジー要素

2022年は、AI(人工知能)やNFT、メタバース、デジタルツイン、Beyond 5G(6G)、DX(デジタルトランスフォーメーション)、XR(クロスリアリティ)、ロボティックスなどがテックシーンを賑わせた。AIは、自動運転車、スマート農業、ライフケア、スマートロボット=写真、チャットボットをはじめ、ほぼすべての産業やビジネスに波及しており、従来の製品・サービスの再発明やタスクの自動化を促している。さらに、人類が影響を被っている、地球と生態のもろもろの課題・問題の解決にも不可欠になっている。
メタバースは、多層化、多重化へ向かっており、没入感のあるデジタル体験を共有しながら、フィジカルリアリティとリンクして、人間世界を拡張するパラレルワールドになっている。外見や物理空間にとらわれず、人と人とが心と心、魂と魂とが触れ合い、つながり合う空間でもあり、心だけで純粋に接客・応対できる空間にもなる。このため、マイノリティの人がどこからでも接客できるダイバーシティ&インクルージョン(社会的包摂)にもつながっている。
メタバースの標準規格の非営利団体「The Metaverse Standards Forum」も2022年6月に設立された。この団体を運営する米Khronos Group(クロノスグループ)は、3DグラフィックスやXRなどの標準規格を策定する技術コンソーシアムであり、メタバースの接続性と空間コンピューティングの相互運用を目指している。
メタバースとのかかわりも深いXRは、VR(仮想現実)、AR(拡張現実)、MR(複合現実)、SR(Substitutional Reality:代替現実)の総称だが、異空間に新たな世界を生み出している。さらに、現実の世界を操作するインタフェースにもなり、AIと連携することにより、産業領域での利用拡大につながっている。
メタバースとXRは、ある種のサイバーフィジカルシステムであり、現実の世界のロボッティックスや各種システムとをつなげることで、人間の物理的な空間の制限をなくして、インタラクションできる手段を提供することにもなる。
これらの活性化により、その表示デバイスとなるマイクロ有機ELディスプレイ(OLEDoS:Organic Light Emitting Diode on Silicon)の市場規模が広がっており、2023年にはさらに高輝度・高解像度のスマートグラスやヘッドセットが実用化される見込みである。
DXは、既成概念や働き方の見直しにつながっており、「分散化」「オンデマンド化」「パーソナライズ」を促進させている。このDXを加速するノーコード、ローコードも話題となった。ノーコードとは、ソースコードのコーディングをせずに、プログラミングの専門知識を必要としないで開発をすることが可能な手法を指す。ツール類は、機能やテンプレートで決まっていたりするため、小規模なアプリケーションや、単純なアプリケーションの開発ができる。ローコードとは、ゼロ(0)からコーディングをするよりも、少ないプログラムコードで開発する手法である。機能は限定的にはなるが、再利用可能な機能構造を利用することで、拡張性を確保することができる。
米ハリウッドではAIが映画業界をサポート
内閣府の戦略的イノベーション創造プログラム(SIP)に関連する、海外の技術動向を追うこのレポートでは、主要なテックシーンのトレンドをクローズアップしてきた。
2022年に話題となり、2023年のトレンドにつながりそうなのが、AIを利用して音楽や画像を生成できるプログラム「コンテンツ生成AI」である。
音楽生成AIは、曲の断片からメロディを生成したり、自動作曲するモデルがあり、音楽自動生成サービスも提供されている。画像生成AIは、「AI画像ジェネレーター」とも呼ばれ、その数がしだいに増えている。静止画だけでなく、動画の生成もできるようになっている。
コンテンツ生成AIは、テクノロジーを先取りしてきた米ハリウッドでは、いまやなくてはならないツールになっている。「DeepStory」や「Saasbook」に代表されように、AIを使ったスクリプト・アシスタントやジェネレーターが使用されている。DeepStoryは、人間がする脚本執筆を手助けしており、ビックデータの解析能力と機械学習能力を組み合わせて、ハイブリッドで創作支援している。Saasbookも脚本の執筆を補助するツールである。

2015年に公開されたホリデー映画『Santa's Helpers(サンタのリトル・ヘルパー)』の告知には、AI で生成されたポスター=写真=もある。その作品が人間によるものか、AIによるものかは、なかなか区別がつかないはず。2016 年には、ニューラルネットワークによるAI を使って、9分間のSF短編映画『Sunspring(サンスプリング)』が、オスカー・シャープ(Oscar Sharp)監督により実験的に製作された。シリコンバレーの俳優のトーマス・ミドルディッチ(Thomas Middleditch)が主演し、テクノロジーや政治、社会全般のニュースやオピニオンを報じる Ars Technica で配信された。いまやハリウッドでは、映画の視聴者分析やマーケティングに、AIを活用しており、アイデアを錬って、完全なスクリプトを作成できるようになるまで、そう遠いことではないかもしれない。
一方で、Music Video Maker の「Nova A.I.」や「Rotor Videos」に見られるように、さほどストーリー性を求められないミュージックビデオの世界では、映像制作にAIを利用する事例が増えている。YouTube上では、そうしたビデオの投稿が珍しくなくなっている。これまではインディーズ系が多数を占めていたが、今後はメジャー系も増えていくと見られる。
コンテンツ生成AIの利用には、専門知識が必要だったり、導入経費がかかったりして、業務系に限定されてきた。それが、2022年には一般の人にまで瞬く間に広がった。絵をまったく描いたことがない人でも、AIのサポートによりゼロからアートを作成できるからだ。
今回のレポートでは、画像やグラフィックス、アート、動画の作成を根底から変えてしまう可能性がある画像生成AIを中心に、その周辺をクローズアップする。
この画像生成AIは、ディープニューラルネットワーク(DNN:Deep Neural Network)と、インタフェースとなる自然言語生成モデルが組み合わさることで誕生し、2021年から2022年にかけて性能を格段に高めた。
Stable Diffusionが画像生成AIブームの火付け役に

2022年に画像生成AIの世界的なブームの起爆剤になったのが、同年8月に英Stability AI(ステービリティAI)が初版を公開した「Stable Diffusion(ステーブル・ディフュージョン)」=写真=である。これは、自然言語で入力されたテキストプロンプトを入力するだけで印象的なビジュアルを作成できる魔法のツールである。プロンプトとは、ユーザーがイメージを生成するためにマシンに入力するテキストの説明のことを指している。こうしたツールがさらに発達していけば、XRコンテンツや販促動画にかかるコストや時間を大幅に削減することにつながる。Stable Diffusionの画期的なことは、テキストから画像を生成する「Text to Image(テキストから画像を生成)」のタスクを実現したことだが、それだけではない。世界中のだれでもが利用できるオープンソース・プログラムとしてリリースされ、画像生成AIの利用を世界中に拡大したことである。このツールは、8GB程度のVRAMのあるGPUを搭載した消費者向けPCのパフォーマンスがあれば実行できてしまうのだ。
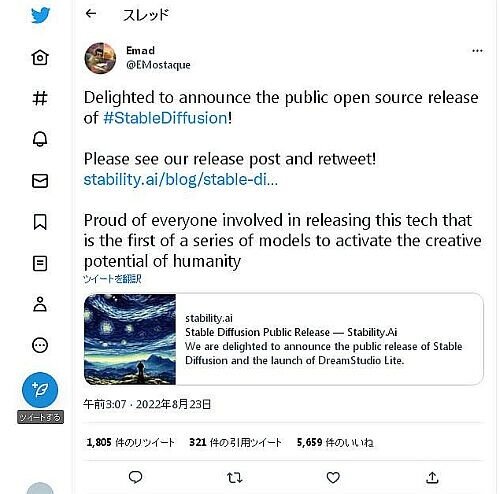
画像生成用のAIを学習させるためには、かなり高額なGPUパワーのハードウェアが必要となる。それだけに無償公開に踏み切ったことが大きな話題となった。Stability AIの創設者であるエマド・モスターク(Emad Mostaque)氏は、2022年8月23日にTwitterで「人類の創造的な可能性を活性化する一連のモデルの最初の技術である、このリリースに関わったすべての人を誇りに思う」=写真=とコメントしている。このデモンストレーションとして、Stable Diffusionのオープンβ版が「DreamStudio」として公開された。こちらは、画像の幅、高さ、処理回数、画像生成に使用するシード値(乱数をつくるときに設定する値)など、細かな調整やスピーディな生成ができる有料サービスになっている。メールアドレスを登録するか、Googleのボイス・ビデオ・テキストコミュニケーションサービスのDiscordアカウントを連携させて登録すると、2ポンド分の200クレジットが付与される。画像のサイズや類似度、処理回数などを設定すると、必要なクレジットも変化する。基本設定では、1クレジットで1画像を生成できる。無料で試すこともできる。Stable Diffusionをブラウザーから直接アクセスして無料で使うことのできるWebサービス「Mage(Mage.space)」(https://www.mage.space/)も登場している。解像度は最大3072ピクセル。正方形では2048×2048ピクセル。ネガティブプロンプトの設定をすれば、生成画像に含ませたくない要素を指定することもできる。ここでは、成人向け描写を規制するセーフティーフィルターが解除されている。
こうした画像生成AIでは、自分が追い求めている画像を生成するためには、さまざまな文字列を大量にプロンプトとして入力する必要がある。この複雑なプロンプトを探ることが画像を生成するうえで、とりわけ手のかかる作業になる。この「呪文」とも呼ばれているキーワードをまとめたサイト「KREA」(https://www.krea.ai/)もできている。
Stable Diffusionの原点を探ると、ミュンヘン大学のCompVisグループが開発した潜在拡散モデル(Latent Diffusion Model)があり、深層生成ニューラルネットワーク(Deep Generative Neural Network)のひとつであることが分かる。
高品質な画像を生成するAIモデル「DALL-E 2」
画像生成AIは、Stable Diffusionが初めてではない。米サンフランシスコに拠点を置くAI企業のOpenAIは、Stability AIより早い時期の2022年4月に、入力したテキストの内容を反映した高品質な画像を生成するAIモデル「DALL-E 2(ダリ・ツー)」を発表している。当初は、研究者に利用を限定していたが、同年7月に一般にも公開し、翌8月にはベータ版を100万人に提供するとともに、生成した画像の商用利用も可能にする有料サービスの提供を決めている。有料による生成であれば、画像はテレビや映画のコンセプトアート、印刷物の挿絵、パンフレット、ゲーム、マーケティングなどに使用することができる。OpenAIがAI 画像生成ソフトウェア「DALL-E」を最初に発表したのは2021年1月。ここから限定的に導入され、テキストから画像への AI ジェネレーターのパイオニアになった。
DALL-E 2は、現在では無料でも使用できる。最初の1カ月は無料で50クレジットが付与され、その後は15クレジットが付与される。15ドルで 115 クレジットの購入ができ、460枚の画像を生成できる。4 テキストプロンプト当たり約 13 セントに相当する。1回作成すると 4 種類のイメージが生成される。
クレジットが消費されるのは、生成が入力されて完了してから。コンテンツポリシーに違反したりして、作品が生成されなかったときは、クレジットは消費されない。生成された画像には、透かしが挿入される。ただし、コンテンツポリシーとして、有害、詐欺的、政治的なコンテンツが禁止されている。ディープフェイクを防止するため、多くの有名人の名前は入力用語として使用できなくなっている。たとえ許容されても、顔がゆがんで描写されたりして、フェイクだと分かるようになっている。
ちなみに、DALL-E の名称は、シュルレアリスム(シュールレアリズム)の画家であるサルバドール・ダリと、ピクサー・アニメーション・スタジオとウォルト・ディズニー・ピクチャーズが製作した長編アニメーション映画『WALL-E(ウォーリー)』をもじって付けられた。
少しわき道にそれるが、OpenAIは、2015年にTesla(テスラ)のCEOであるイーロン・マスク(Elon Reeve Musk)氏が、米カリフォルニア州マウンテンビューのシードアクセラレーターであるY-CombinatorのCEOに就くサム・アルトマン(Sam Altman)氏と共同設立したAI研究の非営利組織である。イーロン・マスク、サム・アルトマンの両氏のほか、オンライン決済サービスのPayPalの創業者ピーター・ティール(Peter Thiel)氏 や ビジネス特化型SNSのLinkedIn の共同創設者リード・ホフマン(Reid Hoffman) 氏を含むシリコンバレーの有名人が2015 年に10 億ドルを投資している。
2015 年 12 月にOpenAI は、そのWebサイトで、「人類全体に利益をもたらす可能性が最も高い方法でAIの開発に焦点を当てた非営利団体を設立する」ことを宣言している。
現在使われている多くのAIは、音声認識や自然言語処理など特定の分野に特化した「特化型AI」と呼ばれるものだ。これはビックデータに基づいて、さまざまな予測ができるため、ほぼ全ての産業分野へ広がっている。これに対し、人間と同じように、さまざまな課題・問題を総合的に判断して処理できるAIは「汎用人工知能(AGI:Artificial General Intelligence)」と呼ばれている。OpenAI が取り組んでいるのは、このAGIの開発であり、ロボットなどによる悪用を防ぐことも掲げている。
ここ数年間の活動だけを見ても、ルービックキューブを解くことを学習するロボットハンドやeSports世界チャンピオンを下したゲームAI「OpenAI Five」のほか、10 種類の楽器で 4 分間の楽曲を生成し、カントリーからモーツァルト、ビートルズまでのスタイルを組み合わせることができるディープニューラルネットワーク「MuseNet」とともに、「アーティスト」「ジャンル」「歌詞」「音楽サンプルの長さ」を指定するだけで、自動的に作曲し、歌唱するWAV(Waveform Audio File Format)ファイルを生成するツール「OpenAI Jukebox」を生み出している。
なお、2019年7月に、Microsoft(マイクロソフト)がOpenAIに10億ドルを出資することを決めており、2018年2月にはイーロン・マスク氏は幹部職を退任している。
OpenAIのGPT-3はわずかな指示から詩や短編小説、楽曲を作成
OpenAIは、Google の ジェイコブ・デブリン(Jacob Devlin )氏と彼の同僚によって作成され公開されたBERT(Bidirectional Encoder Representations from Transformers)などで使用されるTransformer(トランスフォーマー)と呼ばれる深層学習の手法を用いた言語モデルGPT(Generative Pretrained Transformer)を2018年に発表して話題を振りまいた。BERTは、言語モデルが進化する上で、ひとつのマイルストーンになった。これにより、文法にそって一般常識にも見合うだけの長文を生成できるようになったからだ。
GPTは、テキストを入力して、文章を出力させる革新的な高性能の大規模言語モデルである。OpenAIが開発した似たものとして、Codex(Code Extension Model)がある。これはテキストまたはプログラミングコードを入力すると、プログラミングコードを出力するモデル。また、GitHub Copilotもある。これはCopilotと略されて呼ばれるが、Codexを使用して、各種コードを学習させたVisual Studio Code(VS Code)の拡張機能である。VS Codeは、Microsoftが提供する無償のコードエディターである。GitHub という冠がついているように、Microsoft傘下のソフトウェア開発プラットフォームであるGitHub(ギットハブ)が管轄している。
このうち、GPTについては、2019年にGPT-2、2020年にGPT-3とバージョンアップしており、2023年2月頃までにはGPT-4がリリースされることになっている。GPT-3は1750億以上のパラメーター(変数・文字列)を持ち、2018年に提案されたGPT-1の1億1700万パラメーターに比べ、約100倍も規模が増加している。GPT-3は、オンライン上の掲示板で、あたかも人間のように1週間ぐらい会話できるほど、自然な文章を生成することができる。
GPT-4では、AIの能力を確かめるためのチューリングテストにより、インタラクションの対象があたかも人間であるかのように、ユーザーに納得させるために、より多くのパラメーターが設定されると見られている。このため、より自然なインタラクションができるようになると期待されている。
AIモデルの中でも、とりわけGPT-3は評価が高く、わずかな指示だけで詩や短編小説、楽曲などを作ることができる。それが人間の作ったものだと信じこませるくらいのレベルの高さになっている。
2022年11月30日には、GPT-3を組み込んだチャットアプリケーションとして、AIチャットボット「ChatGPT(チャットGPT)」のテスト版が一般公開され、この大規模対話型言語モデルは、リリースしてから6日間でユーザー数が100万人を突破してしまった。
デモ版もリリースされた。これは、対話形式でユーザーの質問に回答したり、おしゃべりするほか、コードの生成や、コードのデバッグ、コードの解説、文章の要約や添削などもできる。ときどき無意味な回答をすることもあり、完全とは言えないが、人間が書くような文章を生成できるようにトレーニングされている。コンテンツは、何百万ものWebサイトからの情報を合成して生成されている。このChatGPTは、GPT-3の学習モデルを改良して作り出した文章生成AIである「InstructGPT(インストラクトGPT)」の姉妹モデルである。
コンテンツ生成AIの多くが、GPT-3に代表されるオープンソース・アルゴリズムに基づいて開発されている。
GoogleからImagen VideoとPhenakiの動画生成AI
画像生成AIに話をもどそう。米Googleも2022年5月に、奇抜なテキストからも画像を自動生成できるAI「Imagen(イマージェン)」を発表した。同年10月には、約5秒間の動画を生成できる「Imagen Video(イマージェンビデオ)」も公開している。
このImagen Videoでは、入力されたテキストをGoogleの自然言語処理モデル「T5」で処理し、映像を生成する拡散モデルで「Video Diffusion Models」がベースとなる映像を生成する。この時点では、解像度は24×48ピクセルで、毎秒3フレームで16枚(約5.3秒)に過ぎないが、これを時間的超解像度(TSR:Temporal Super-Resolution)モデルで各フレームの間を埋める補間画像を追加し、空間的超解像(SSR:Spatial Super-Resolution)のモデルでフレームを拡大することを各3回実行し、最終的に1280×768の解像度と毎秒24フレームで128枚(約5.3秒)の動画を生成する。
このように時間方向と空間方向の2種類の超解像度拡散モデルを組み合せて、最初に生成した低解像度のフレームを高解像度、高フレームレートの動画に仕上げていくカスケード拡散モデル(Cascaded Diffusion Models)という仕組みを採用している。アーティストの画風を取り入れたり、3D構造を認識して、動画内に3Dモデルを登場させたりすることも可能である。
Googleは、Imagen Videoだけでなく、2022年10月に「Phenaki(フェナキ)」という動画生成AIも発表した。Phenakiは、Imagen Videoより長めのストーリー性のある動画を生成できる。動画をトークンに圧縮するC-ViViTと呼ばれるエンコーダー/デコーダー・モデル(Encoder-Decoder Model)と、テキスト特徴量を動画トークンに変換する自己回帰的モデル(Autoregressive Model)のTransformerの2つの主要モデルからできている。C-ViViTは、時間の自己回帰を維持しながら、時間的・空間的な次元でビデオを圧縮することにより、ビデオの時間情報を活用する構造により、可変長のビデオをエンコードおよびデコードする。入力文章であるプロンプトをテキスト特徴量に圧縮するために、学習済みの言語モデルであるT5の改訂版「T5X」を使用した。
ここでトークンと呼ばれるのは、英語のアルファベットの文字のようなものであり、機械が計算しやすいように断片化された概念を表し、アルゴリズム用の言語に配置されている。人間が読めるテキストをマシンが読めるテキストに自動的に翻訳する方法は、「Transformer Model(トランスフォーマーモデル)」と呼ばれている。
Googleは、人権問題や人種差別を助長させるコンテンツが生成される懸念があるとして、ImagenやImagen Video、Phenakiのソースコードは公開しておらず、一般ユーザーの利用について許可していない。
動画生成AIについては、米Metaが2022年9月にテキストから高画質の動画を生成するAI「Make-A-Video」=写真=を発表している。テキストから動画を生成するだけでなく、1枚の画像の前後を描いて動画にすることもできる。既存の動画に背景や動きをプラスして、別の動画を作成することもできるが、ストーリー性のある長めの動画は作成できない。

画像生成AIで最初の火付け役はMidjourney

画像生成AIで最初の火付け役となったのは、シリコンバレーのスタートアップで従業員数10人程度のMidjourney(ミッドジャーニー)だった。Midjourneyは、2022年7月にテキストを入力するだけで画像生成ができるオンライン AIアートツール(お絵かきAI)として、会社名と同じ画像生成AI「Midjourney」を発表した。このMidjourneyが広く知られるきっかけになったのは、ゲームデザイナーのジェイソン・アレン(Jason Allen)氏が、同年8月26日から9月5日まで開催された第150回コロラド州品評会(The 150th Colorado State Fair)のデジタルアートのアマチュア部門で、Midjourneyで生成した絵=写真=を提出して1位を獲得したからだった。アレン氏は、自身のアートワークを提出したとき、Midjourney で作成されたことを明らかにしており、主催者側は違法性がなかったことを認めている。だが、多くの批判にされさることにもなり、これにより画像生成AIが脚光を浴びるとともに、デジタルアートが新たな段階に入ってことを示した。
アレン氏が描いた絵は、限られた数の単語を使用して、豪華なオペラ公演の模様と宇宙の幻想的な風景を融合させる手法で、3 枚の絵を生成。その一枚が受賞した。照明、遠近法、構成、雰囲気、主題、そのほか絵の属性に作用するキーフレーズを試行錯誤して、900を超えるオプションの中から上位 3 枚をレンダリングしたというから、それなりに創作力はあったのかもしれない。
Midjourneyは、一定の機能を無料で提供し、特別な機能は有料にするという、いわゆるフリーミアムのビジネスモデルをとったため、無償公開に踏み切ったStable AIのStable Diffusionが脚光を浴びることになった。
現在、Midjourneyは無料の利用ができるが、その場合には商業利用はできない。無料では25回の画像生成ができるが、解像度を上げて再生成しても1回に数えられている。有料サービスは、月額10ドルで200枚の生成ができる。月額30ドル払えば、枚数は無制限になる。そのほかに、月額600ドルのコーポレート(法人)プラン(年間総収入100万ドル以上の企業の従業員またはオーナー)がある。コーポーレートプランには、最大 12か月分を前払いし、返金不可のデポジット(保証金・預かり金)が含まれる。有料サービスであれば、商用利用もできる。
Midjourneyのシステムは、チャットサービスのDiscordのサーバー内で運営されている。このため、Midjourneyに申し込むと、Discord に送られ、アカウントの開設が求められ、初心者向けチャンネルへの招待が届く。この画像生成AIは、指示した情報から4パターンの画像を生成する。サイズは512×512ピクセル。気に入った画像があれば、単体で1024×1024ピクセルに解像度を上げて仕上げることができる。「Community Feed」では、公開済みになった世界中の作品を見ることができ、非営利目的であれば、画像の保存、コピー、リミックスを認めている。
こうした画像生成AIの研究開発は、2015年頃から大学や研究機関が取り組みを本格化したが、OpenAIが DALL-E 2を発表したことで、 飛躍的進歩を遂げている。動画生成AIのアルゴリズムの系譜にかかわったところは、ミシガン大学(University of Michigan)、マックスプランク研究所(Max Planck Institute)、ラトガース大学(Rutgers University)、リーハイ大学(Lehigh University)、香港中文大学、MSR(Microsoft Research)、アレン AI 研究所(Allen Institute for AI)など数多い。
いまや画像生成AIは、DALL-E 2、Midjourney、Stable Diffusion、Imagen、Imagen Video、Phenakiのほかにも、Jasper Art、NightCafe、Photosonic、Artbreeder、StarryAI、DeepAI、Deep Dream Generator、Fotor、RunwayMLなどと増え続けている。
ページ数が許される範囲で、主な画像生成AIの概要をまとめてみた。料金や規約は変更される可能性がある。
Jasper Art(ジャスパーアート)
Jasper Art(ジャスパーアート)
米テキサス州オースティンに拠点に2021年に創業したスタートアップのJasper(ジャスバー)が、DALL-E 2のアルゴリズムを使用して開発し、2022年8月にリリースした。Jasper Art=写真=では、電子透かしのない画像を作成できる。料金は1アカウント月額20ドル。無料でお試しもできる。著作権フリーのストック写真の作成など、マーケティングやブロガーを主なターゲットにしている。各種スタイルやオプションから選択するだけで、表現方法のカスタマイズができる。スタイルは、ピクセル、ベクターアート、ラインアート、3Dレンダリング、レトロなど、13種類。モダンな油絵、鉛筆スケッチ、チャコール、パステルなど、15種類の作風・画風のオプションからも選択できる。幸せ、悲しい、攻撃的、鈍い、エネルギッシュといった気分についても、19種類のムードから選択できる。画像は数秒で生成される。アートワークをダッシュボードに保存しておけば、過去の自身の作品を振り返ることができる。
Jasperは、文章作成をサポートするAIコンテンツプラットフォームであるJasper AI(Jasper.ai)も開発している。これも労力と時間をあまりかけないでコンテンツを作成できる。対応言語は、英語(米語とイギリス語)、フランス語、中国語、日本語、ロシア語、スペイン度、ドイツ語、イタリア語、ポルトガル語、ポーランド語、スウェーデン語、フィンランド語、ギリシャ語など26カ国語。
各言語に対応したブログ記事やSNS投稿、Webサイトの広告コピーのほか、ビデオスクリプト(シーン、ショット、アクション、ダイアログを時系列に並べた文章)、セールスレター、メールコピー、キャプションなど広範囲に及ぶ。文章の言い換えや口調の変更も可能。Jasper AIの利用は有料。ただし5日間の無料体験がある。アカウントを作成することで、無料で1万語の文章が書ける特別クレジットがもらえる。
Photosonic(フォトソニック)
Photosonic(フォトソニック)
Photosonicは、Webブラウザー上で、テキストから画像を作成したり、画像を別のクリエイティブスタイルに変換したりできる AI 画像生成ツール。生成された画像は、512×512ピクセルの解像度でダウンロードできる。
プロフェッショナル向けというより、初心者に使い勝手のいいサービス。独自のキーワードを追加してアートワークを改良することで、特定のスタイルをミックスしたり、マッチングさせたりできる。
クラウドの個人ギャラリーに生成画像を保存できる。また、オープンソースのブログソフトウェアであるWordPress(ワードプレス)や、 ブログ型コンテンツ発信プラットフォームのMedium(ミディアム)、グラフィックデザインツールのCanva(キャンバ)など、他のプラットフォームにエクスポートすることもできる。
クレジットなしで作成した画像を商業的に使用できる。生成されるアートワークは、生真面目な画像というより、抽象性が高くなったり、漫画的に見えたりすることがある。
有料サービスでは、月額10ドルで100 クレジットを獲得でき、100枚の画像を生成できる。月額25ドル払えば無制限のクレジットを購入できる。サインアップすると、15 クレジットが提供される無料トライアルがある。
NightCafe(ナイトカフェ)
NightCafe(ナイトカフェ)
NightCafe=写真=は、使いやすい画像生成AI。サインアップしてアカウントを開設する必要がなく、すぐに試してみることができる。アルゴリズムとアートの生成機能が豊富にそろっている。テキストプロンプトを入力し、スタイルを選択するだけで生成できる。最初のページで、「NightCafe(ナイトカフェ)」「Artistic Portrait(芸術的な肖像画)」「Bon Voyage(よい旅を)」の 3種類のスタイルから選択できる。NightCafeでは、ダークな感じの絵画風に、Artistic Portraitは文字どおり人物が中心の肖像画に、Bon Voyageは空想的・幻想的な感じになる。いったん生成したら「view creation」に進むと、その画像をベースに、設定を微調整して、画像を進化させることができる。生成をもう一度やり直したいときは、新しいイメージの作成に進み、作成方法を選択する。カスタマイズのオプションで25種類のアートワークのスタイルが選択できるため、1 回のプロンプトで多数の画像を生成できる。
ユーザーが出力するアートスタイルを選択できるだけでなく、AIが使用するアルゴリズムも選択できる。さまざまな種類の画像を生成することができる。出力画像をアップスケールしたり、より多くのテキストプロンプトを入力できるようにするためには、多くのクレジットが必要となる。
アカウントを作成すると、1日5クレジットが与えられる。 1クレジットでアートワーク作品を作成できる。さらに、毎日午前零時に無料で5 クレジットを受け取ることができる。無料サービスは機能が制限されている。有料サービスは月額9.99ドルで100クレジットが購入できる。価格は1クレジットあたり0.053ドルという低価格。
NightCafeで作成されたアートワークの知的財産権は制作者に譲渡される。個人的および商業的な目的で使用することが可能。ただし、そのアートワークの商標や著作権を保護できる保証はないとしている。
Craiyon(クレヨン) <旧名:DALL・E mini>
Craiyon(クレヨン) <旧名:DALL・E mini>
Craiyonは、テキストを入力するだけで、9つの画像を自動生成するシステム。2021 年 7 月に、Google と Hugging Face と呼ばれる AI コミュニティが開催したコンペティションの一環として、プログラムが作成された。
詳細は、DALL・E Mini Model Card(https://huggingface.co/dalle-mini/dalle-mini)に記載されている。 AIモデルを訓練したのはプログラマーのBoris Dayma氏、サーバーのバックエンドを作成したのはPedro Cuenca氏とされている。
OpenAIのDALL・Eの成果を、オープンソースのモデルで再現しているが、Dall-E 2とは関係がない。その名称から分かるように、オリジナルのDALL·Eプロジェクトとの混同を避けるため、OpenAIからの要請もあり、Craiyonという名称を変更した。
Webサイトバージョンのほか、Google Play Storeから Android デバイスで利用できるアプリがある。
無料で制限なく使用できる。プロンプトごとに、 3×3 グリッドの形式で9枚の画像が生成される。納得がいくまで、試行を繰り返すことができる。画像の生成までには 1 分程度かかる。抽象画を得意とするが、顔の描画については、さほどうまく出力しない傾向がある。砂漠の風景はリアリティがあるという評判。
Craiyonは、DALL・Eの27分の1のモデルサイズで、当初はminiと名付けられた。当初の画像サイズは256×256ピクセル程度だが、ブログのイラスト程度なら十分に使える。DALL・Eの1024×1024ピクセルより小さかった。今後、サイズの拡大計画はある。
Artbreeder (アートブリーダー)
Artbreeder (アートブリーダー)
Artbreeder=写真=は、フォトリアリスティックなアートジェネレーターで、他のツールでは難しい抽象写真のような画像生成に向いている。AI を使用して、テキストから画像を生成するだけでなく、 既存の画像を組み合わせたり、画像をアップロードして画質を向上させたり、さまざまなバージョンを作成したり、アニメーションのポートレートにしたりできる。このツールの特徴は、何千ものイラストが用意されていること。これらのイラストをリミックスして、新しい作品をまとめて作成できる。独自の画像とリミックスして、コラージュの作成もできる。例えば、「Splicer(スプライサー:つなぎ合わせるモノや人)」ツールを使用すれば、一枚の画像の異なるバージョンを作成できる。「Edit-Genes(遺伝子編集)」では、性別、年齢、人種、髪色、瞳の色、表情などの遺伝子要素を細かく調整することが可能。生成できる画像の種類は、General(一般)、Portraits(肖像画)、Characters(キャラクター)、Albums(アルバムジャケット)、Landscapes(景色・景観)、Anime Portraits(アニメ肖像画)、Portraits Old(古い肖像画)の7種類。多くの機能が無料で提供されているが、アップロードする画像(3枚で無料)を増やしたいときや、より高度な生成がしたいときには、月額8.99 ドルの有料サービスがある。ランドスケープの変換をしたり、NFT アートのジェネレーターもある。作成された全作品は、クリエイティブ・コモンズ(CC)のライセンスのもとで自由に使用できると見なされる。すべての画像はパブリックドメインで公開され、帰属の有無にかかわらず、あらゆる目的で、あらゆる人物によって使用される可能性がある。NFTとして、アートワークとMint(ミント)の作成もできるが、CCライセンスのもとで同じ画像にアクセスでき、同じアートワークを作成することもできてしまう。
StarryAI(スターレイAI)
StarryAI(スターレイAI)
StarryAI は、ユーザーのアイデアから NFT アートワークを生成することに特化したツール。他の画像生成AIと同様、テキストプロンプトを入力して作成を開始する。Webサイトにアクセスして、オンラインポータルから直接画像の作成ができるが、手軽に始めたければモバイル・アプリケーション(iOS/Android)がある。モバイル版を利用すれば外出先で画像の生成ができる。
毎日無料で5クレジットが提供される。電子透かしのない25枚のアートワークを作成できる。生成画像の所有権はユーザーにあり、自由に使うことができる。さまざまなスタイル、モデル、初期画像、縦横比を使用して製品をカスタマイズできる。TwitterやInstagram、TikTok、Reddit でアートワークを共有したり、広告を視聴することでもクレジットを獲得できる。
生成素材としてカスタム画像を選択することもできる。試用するのに、クレジットカードを登録する必要はないが、無料のオプションは少なめ。有料プランであれば、多くの機能を使うことができ、多くのアートワークを見ることができる。有料サービスであるStarryAI Pro は、月額17.49ドルで 50クレジットを購入できる。
スタイルの選択画面では、各ボタンにはアーティストの名前と、そのスタイルを表す背景画像が表示され、一度に最大 10 人のアーティストを選択できる。アニメポートレート(アニメ肖像画)、デジタルアート、グラフィック、鉛筆画などからアートスタイルを絞ることができる。
<つづく>
(清水メディア戦略研究所 代表)